数据分析-数值计算(Numpy、Pandas)
Numpy
NumPy 简介
NumPy(Numerical Python的简称)是一个开源的Python科学计算库,专门用于进行大规模数值计算。它由Travis Oliphant在2005年创建,最初是作为另一个库NumPy的继承者。NumPy是许多其他科学计算和数据分析Python库的基础,如Pandas、SciPy和Matplotlib。
以下是NumPy的一些关键特性:
多维数组对象`ndarray`:NumPy的核心是一个强大的N维数组对象,称为`ndarray`。这个数组对象提供了高效的存储和操作大型多维数组的能力。
广播功能:NumPy的广播规则允许不同形状的数组之间进行算术运算,这大大简化了数组操作。
高效的数学函数:NumPy提供了大量的数学函数,这些函数都是在底层用C语言编写的,可以快速执行元素级数组运算。
线性代数、傅里叶变换和随机数生成:NumPy包含了线性代数、傅里叶变换和随机数生成等功能,这些都是科学计算中常用的操作。
内存使用和性能:NumPy的数组是存储在连续的内存块中的,这使得NumPy数组比Python的内置列表在处理大型数据集时更加高效。
兼容性和集成:NumPy可以很容易地与其他Python库和工具集成,如SciPy、Pandas、Matplotlib等。
广泛的社区支持:作为一个广泛使用的库,NumPy拥有一个活跃的社区,提供了大量的文档、教程和第三方工具。
NumPy的基本用法包括:
创建数组:可以通过`np.array`函数从Python列表或元组创建NumPy数组。
数组运算:支持数组间的加、减、乘、除等算术运算。
数组切片和索引:可以像处理Python列表一样对NumPy数组进行切片和索引。
统计函数:提供了计算平均值、中位数、标准差等统计量的函数。
线性代数:提供了矩阵乘法、特征值、奇异值分解等线性代数操作。
随机数生成:可以生成各种分布的随机数。
NumPy是Python科学计算生态系统的基石,它的高性能数组处理能力使得Python成为进行复杂数值计算的有力工具。
创建数组
1. 从列表或元组创建数组
NumPy 用于处理数组。 NumPy 中的数组对象称为 ndarray。
最直接的方法是从Python的列表或元组转换为NumPy数组。
import numpy as np
# 从列表创建一维数组
list_arr = [1, 2, 3, 4, 5]
array_from_list = np.array(list_arr)
# 从元组创建二维数组
tuple_arr = (1, 2, 3)
array_from_tuple = np.array(tuple_arr)要创建 ndarray,我们可以将列表、元组或任何类似数组的对象传递给 array() 方法,然后它将被转换为 ndarray
2. 使用np.zeros
创建一个填充了零的数组。
# 创建一个形状为(3, 4)的二维零数组
zeros_array = np.zeros((3, 4))3. 使用np.ones
创建一个填充了一的数组。
# 创建一个形状为(2, 3, 4)的三维一数组
ones_array = np.ones((2, 3, 4))4. 使用np.full
创建一个填充了指定值的数组。
# 创建一个形状为(2, 2)的二维数组,填充值7
full_array = np.full((2, 2), 7)5. 使用np.arange
创建一个包含等差数列的数组。
6. 使用np.linspace
创建一个在指定范围内均匀分布的值的数组。
# 创建一个包含10个从0到1的均匀分布的一维数组
linspace_array = np.linspace(0, 1, 10)7. 使用np.eye
创建一个单位矩阵。
# 创建一个3x3的单位矩阵
eye_array = np.eye(3)8. 使用np.random.rand或np.random.randn
创建一个给定形状的数组,填充随机数。
# 创建一个形状为(3, 4)的二维数组,填充0到1之间的随机数
random_array = np.random.rand(3, 4)
# 创建一个形状为(3, 4)的二维数组,填充标准正态分布的随机数
random_normal_array = np.random.randn(3, 4)9. 使用np.array_split
将一个数组分割成多个子数组。
# 创建一个一维数组
arr = np.arange(10)
# 将数组分割成3个子数组
sub_arrays = np.array_split(arr, 3)10. 使用np.linspace创建多维数组
# 创建一个形状为(2, 5)的二维数组,包含从0到1的均匀分布的值
linspace_2d_array = np.linspace(0, 1, 10).reshape(2, 5)数组索引和切片
NumPy 数组索引是访问和操作数组元素的重要方式。NumPy 提供了灵活的索引和切片功能,允许你高效地选取和修改数组中的数据。以下是一些基本的索引方法:
1. 基本索引
对于一维数组,索引方式与 Python 列表类似:
import numpy as np
arr = np.array([10, 20, 30, 40, 50])
print(arr[0]) # 输出: 10
print(arr[-1]) # 输出: 50,使用负索引从数组末尾开始计数2. 切片
切片用于获取数组的一部分:
print(arr[1:4]) # 输出: [20 30 40],从索引1到索引4(不包括4)
print(arr[1:]) # 输出: [20 30 40 50],从索引1到数组末尾
print(arr[:4]) # 输出: [10 20 30 40],从数组开头到索引4(不包括4)
print(arr[:]) # 输出: [10 20 30 40 50],复制整个数组3. 步长
在切片时,可以指定步长:
print(arr[::2]) # 输出: [10 30 50],选取数组中的每个第二个元素4. 高级索引
NumPy 支持使用数组进行索引,这称为高级索引:
# 使用布尔数组索引
bool_idx = arr > 20
print(arr[bool_idx]) # 输出: [30 40 50]
# 使用整数数组索引
idx = [0, 2, 4]
print(arr[idx]) # 输出: [10 30 50]5. 花式索引
花式索引允许你使用多个索引数组来获取数组的子集:
# 花式索引
i = [0, 2]
j = [1, 3]
arr_2d = np.array([[10, 20, 30], [40, 50, 60], [70, 80, 90]])
print(arr_2d[i, j]) # 输出: [20 60]6. 转置数组
在 NumPy 中,可以使用 .T 属性来转置数组:
print(arr_2d.T) # 输出: 转置后的二维数组7. 多维数组索引
对于多维数组,你可以使用元组来指定索引:
print(arr_2d[0, 1]) # 输出: 20,访问第一行第二列的元素8. 省略号索引
在 Python 3.8+ 中,你可以使用省略号 ... 来表示“取所有元素”:
print(arr_2d[..., 0]) # 输出: [10 40 70],取所有行的第一列9. 布尔数组的索引
布尔数组可以用于索引,其中 True 表示选择该元素:
print(arr[arr > 30]) # 输出: [40 50]10. 条件索引
结合布尔索引和 np.where 函数,可以基于条件选择元素:
idx = np.where(arr > 30)
print(arr[idx]) # 输出: [40 50]数据类型
NumPy 提供了一种强大的数据类型系统,称为 NumPy 数据类型(或 dtype)。这些数据类型是用于指定数组中元素的类型。NumPy 数据类型对于内存效率和执行速度至关重要,因为它们允许 NumPy 以固定大小的块来存储数据,从而实现快速的数组操作。
1. 基本数据类型
NumPy提供了一组预定义的基本数据类型,这些类型覆盖了整数、浮点数、复数和布尔值等。基本数据类型可以细分为:
整数类型:如
int8(8位有符号整数)、int16、int32、int64等。无符号整数类型:如
uint8(8位无符号整数)、uint16、uint32、uint64等。浮点数类型:如
float16、float32(单精度浮点数)、float64(双精度浮点数)等。复数类型:如
complex64(由两个float32组成)、complex128(由两个float64组成)。布尔类型:
bool_,用于存储布尔值True或False。
2. 数据类型对象
在NumPy中,每个数据类型都是一个dtype对象。你可以通过多种方式创建或指定dtype对象:
直接使用类型名称,如
np.int32、np.float64。使用Python内置类型,如
int、float,NumPy会根据上下文推断相应的NumPy类型。使用字符串,如
'int32'、'float64'。
3. 自定义数据类型
NumPy允许你创建自定义的数据类型,这在处理结构化数据时非常有用。自定义数据类型可以是:
结构化数据类型:由多个字段组成,每个字段都有自己的数据类型。例如,定义一个包含姓名(字符串)、年龄(整数)和身高(浮点数)的结构化数据类型。
np.dtype([('name', 'S10'), ('age', 'int32'), ('height', 'float32')])子数组数据类型:在某些情况下,你可能需要数组中的元素本身也是一个数组。NumPy允许你定义这种类型的数据结构。
np.dtype((np.int32, (3,))) # 一个包含三个int32元素的数组
4. 类型转换
在NumPy中,你可以使用astype方法将数组的数据类型转换为另一种类型:
arr = np.array([1, 2, 3], dtype=np.int32)
arr_float = arr.astype(np.float64)5. 类型提升
在进行算术运算时,NumPy会根据参与运算的数组的数据类型进行类型提升,以确保结果的准确性。例如,当你将一个int32数组与一个float64数组相加时,NumPy会将int32数组提升为float64,然后再进行运算。
6. 类型兼容性
NumPy在处理不同数据类型的数组时,需要考虑类型兼容性。例如,你不能直接将字符串数组与整数数组进行数学运算,因为它们的数据类型不兼容。
7. 内存效率
选择正确的数据类型对于优化内存使用至关重要。例如,如果你知道数据的范围不会超过256,那么使用uint8而不是int32可以节省内存。
8. 性能考虑
数据类型也会影响计算性能。在某些情况下,使用较小的数据类型(如float32而不是float64)可以减少内存使用并提高计算速度,但这可能会牺牲一些精度。
随机数生成
随机数概念
随机数定义:随机数是指无法在逻辑上预测的数字。
伪随机与真随机:
计算机生成的随机数基于算法,称为伪随机数。
真正的随机数需要从外部来源获取随机数据,如击键、鼠标移动等。
伪随机数足以满足大多数需求,除非涉及安全性或需要极高随机性的应用。
NumPy 随机数模块
NumPy 提供了
random模块来处理随机数生成。
生成随机数
实例:生成一个 0 到 100 之间的随机整数
from numpy import random
x = random.randint(100)
print(x)
实例:生成一个 0 到 1 之间的随机浮点数
from numpy import random
x = random.rand()
print(x)
生成随机数组
randint()和rand()方法可以接受size参数,用于指定生成数组的形状。
实例:生成一个 1-D 数组,包含 5 个从 0 到 100 之间的随机整数
from numpy import random
x = random.randint(100, size=(5))
print(x)
实例:生成一个 3 行的 2-D 数组,每行包含 5 个从 0 到 100 之间的随机整数
from numpy import random
x = random.randint(100, size=(3, 5))
print(x)
实例:生成包含 5 个随机浮点数的 1-D 数组
from numpy import random
x = random.rand(5)
print(x)
实例:生成一个 3 行的 2-D 数组,每行包含 5 个随机数
from numpy import random
x = random.rand(3, 5)
print(x)
从数组生成随机数
choice()方法可以从给定的值数组中随机返回一个值或生成一个值数组。
实例:返回数组中的值之一
from numpy import random
x = random.choice([3, 5, 7, 9])
print(x)
实例:生成由数组参数(3、5、7 和 9)中的值组成的二维数组
from numpy import random
x = random.choice([3, 5, 7, 9], size=(3, 5))
print(x)Pandas
基础概念
理解 Pandas 的主要数据结构:
Series(一维标记数组)和DataFrame(二维表格型数据结构)。
Series
Series 是 pandas 中的一个一维带有标签的数组,可以包含任何类型的数据,如整型、浮点、字符、Python 对象等。它的轴标签被称为「索引」,索引可以是整数、字符串或日期等。如果创建 Series 时没有指定索引,Pandas 会自动创建一个从 0 开始的整数索引。Series是 Pandas 最基础的数据结构。

1. Series 特点
一维数组:每个元素都有一个对应的索引值。
索引:可以通过标签(索引)访问数据元素,默认索引从 0 开始的整数,也可以自定义索引。
数据类型:可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
注:Series 中的所有元素必须是相同的数据类型。Pandas 会自动推断数据类型,但你也可以显式指定。如果数据类型不匹配,Pandas 会尝试进行类型转换。
大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
操作:支持各种操作,如数学运算、统计分析、字符串处理等。
缺失数据:可以包含缺失数据,使用 NaN(Not a Number)表示。
自动对齐:在对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据。
2. 创建 Series
Series 可以通过多种方式创建,最常见的方法是从 Python 列表、元组、字典或 NumPy 数组创建
语法:
s = pd.Series(data, index=index)data可以是 Python 对象、numpy 的 ndarray、一个标量(如 8)index索引是轴上的一个列表,必须和 data 的长度相同,如果没有指定则自动从 0 开始[0, ..., len(data) - 1]
数据来源
列表元组:直接放入
pd.Series()ndarray:可以是 numpy 的 ndarray
字典 dict:key 为索引,value 为内容
标量(scalar value):一个具体的值,如果不指定索引长度为 1,指定索引后长度为索引的数量,每个索引的值都是它。
import pandas as pd
# 从列表创建 Series
data_list = [1, 2, 3, 4, 5]
s_from_list = pd.Series(data_list)
# 从 NumPy 数组创建 Series
import numpy as np
data_array = np.array([1, 2, 3, 4, 5])
s_from_array = pd.Series(data_array)
# 从字典创建 Series
data_dict = {'a': 1, 'b': 2, 'c': 3}
s_from_dict = pd.Series(data_dict)
# 从标量创建 Series
pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])3. Series操作
类似 ndarray 操作:支持切片、数学函数、筛选、指定索引的内容等。
类似字典的操作:通过 key 进行取值,增加数据,检测索引等。
向量计算和标签对齐:同索引相加、相乘、选取部分进行计算等。
名称属性:Series 可以指定一个名称,如无名称则不返回内容(NoneType)。
# 类ndarray
s = pd.Series([1,2,3,4,5,6,7,8])
s[3] # 类似列表切片
s[2:]
s.median() # 平均值,包括其他的数学函数
s[s > s.median()] # 筛选大于平均值的内容
s[[1, 2, 1]] # 指定索引的内容,括号的列表是索引
s.dtype # 数据类型
s.array # 返回值的数列
s.to_numpy() # 转为 numpy 的 ndarray
3 in s # 逻辑运算,检测索引
# 类字典
s = pd.Series([14.22, 21.34, 5.18],
index=['中国', '美国', '日本'],
name='人口')
s['中国'] # 14.22 # 根 key 进行取值,如果没有报 KeyError
s['印度'] = 13.54 # 类似字典一样增加一个数据
'法国' in s # False 逻辑运算,检测索引
# 向量计算和标签对齐
s = pd.Series([1,2,3,4])
s + s # 同索引相加,无索引位用 NaN 补齐
s * 2 # 同索引相乘
s[1:] + s[:-1] # 选取部分进行计算
np.exp(s) # 求e的幂次方
# 名称属性
s = pd.Series([1,2,3,4], name='数字')
s.name # '数字'
s = s.rename("number") # 修改名称
s2 = s.rename("number") # 修改名称并赋值给一个新变量# 其它常用方法
s = pd.Series([1,2,3,4], name='数字')
s.add(1) # 每个元素加1 abs()
s.add_prefix(3) # 给索引前加个3,升位
s.add_suffix(4) # 同上,在后增加
s.sum() # 总和
s.count() # 数量,长度
s.agg('std') # 聚合,仅返回标准差, 与 s.std() 相同
s.agg(['min', 'max']) # 聚合,返回最大最小值
s.align(s2) # 联接
s.any() # 是否有为假的
s.all() # 是否全是真
# 2.0 版本已经取消,用 pd.concat(s1, s2)
s.append(s2) # 追加另外一个 Series
s.apply(lambda x:x+1) # 每个元素应用方法
s.empty # 是否为空
s3 = s.copy() # 深拷贝
s.astype(float) # 数据类型转换
s.sort_values() # 排序4. 缺失值处理
Series 可以包含缺失值,Pandas 使用 NaN(Not a Number)来表示缺失数据。你可以使用 dropna() 删除缺失值,或使用 fillna() 填充缺失值:
# 删除缺失值
s_with_nan = pd.Series([1, 2, np.nan, 4])
s_with_nan.dropna()
# 填充缺失值
s_with_nan.fillna(value=0)DataFrame
数据框(DataFrame):二维数据结构,以行和列的形式排列数据,类似于 CSV、Excel、SQL 结果表或由 Series 组成。它是 Pandas 中最常用的数据结构,非常适合用于数据清洗、处理和分析。
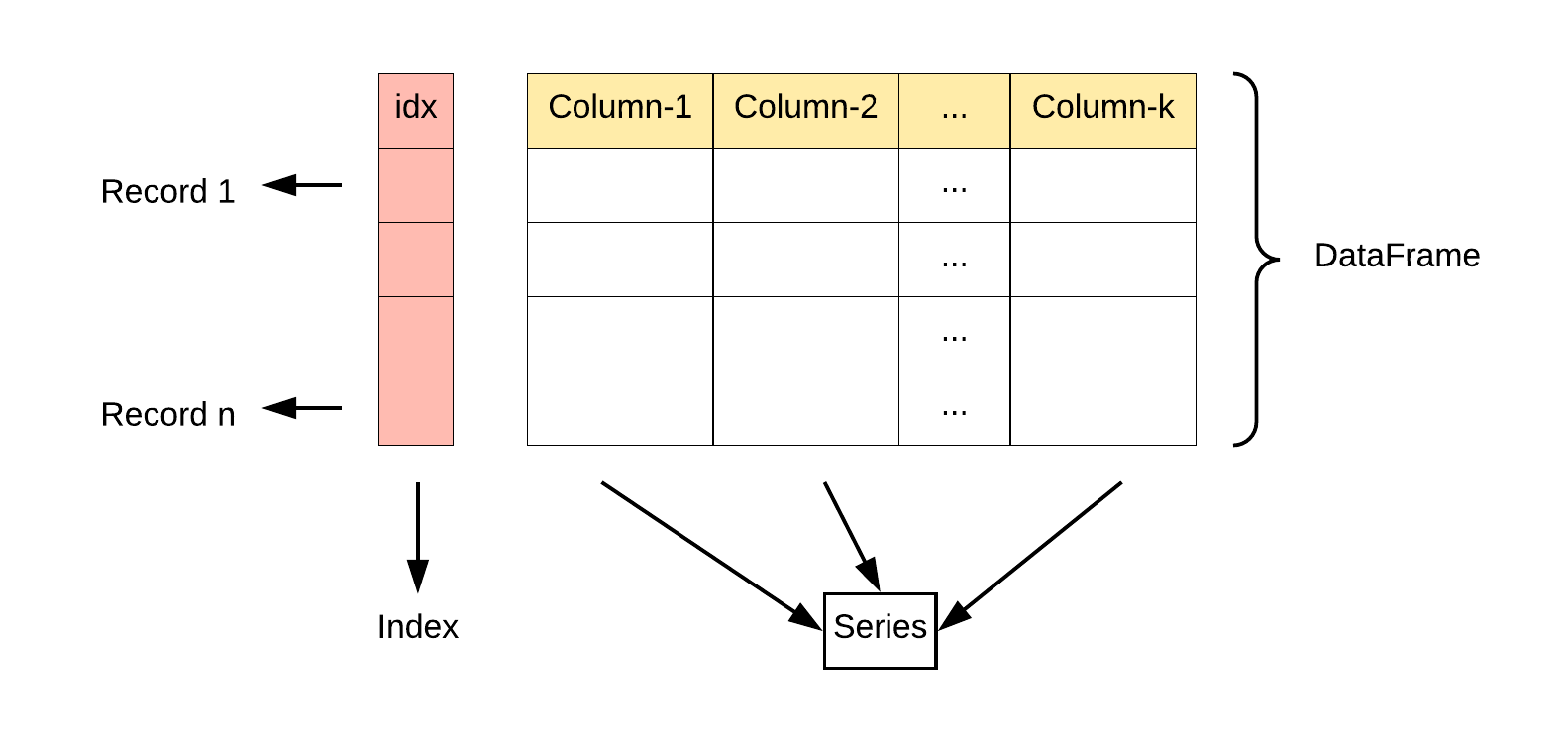
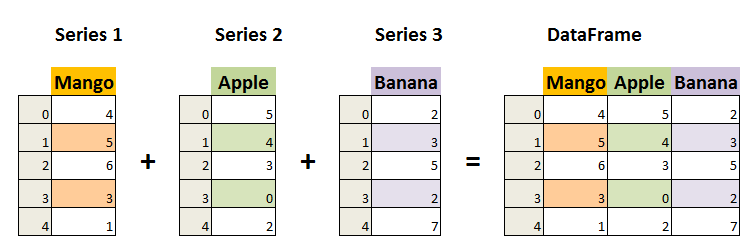
1. DataFrame 特点
二维结构:类似于 Excel 电子表格或 SQL 表,可以视为多个 Series 对象组成的字典。
列的数据类型:不同的列可以包含不同的数据类型。
索引:拥有行索引和列索引,类似于 Excel 中的行号和列标。
大小可变:可以添加和删除列,类似于 Python 中的字典。
自动对齐:在进行算术运算或数据对齐操作时,会自动对齐索引。
处理缺失数据:可以包含缺失数据,使用
NaN(Not a Number)表示。数据操作:支持数据切片、索引、子集分割等操作。
时间序列支持:对时间序列数据有特别的支持。
丰富的数据访问功能:通过
.loc、.iloc和.query()方法,可以灵活地访问和筛选数据。灵活的数据处理功能:包括数据合并、重塑、透视、分组和聚合等。
数据可视化:可以与 Matplotlib 或 Seaborn 等可视化库结合使用。
高效的数据输入输出:方便地读取和写入数据,支持多种格式,如 CSV、Excel、SQL 数据库和 HDF5 格式。
描述性统计:提供了一系列方法来计算描述性统计数据。
2. 创建 DataFrame
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。index:DataFrame 的行索引。columns:DataFrame 的列索引。dtype:指定 DataFrame 的数据类型。copy:是否复制数据。
DataFrame 可以通过多种方式创建,包括从字典、列表、NumPy 数组、其他 DataFrame 或直接从文件(如 CSV、Excel 等)创建。
import pandas as pd
# 从 字典 创建 DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 23, 34, 29],
'City': ['New York', 'Paris', 'Berlin', 'London']}
df = pd.DataFrame(data)
# 从 列表 创建 DataFrame
df_list = pd.DataFrame([['John', 28, 'New York'], ['Anna', 23, 'Paris']], columns=['Name', 'Age', 'City'])
# 从 ndarrays 创建 DataFrame
ndarray_data = np.array([
['Google', 10],
['Runoob', 12],
['Wiki', 13]
])
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])
# 从 Series 创建 DataFrame
s1 = pd.Series(['a', 'b', 'c', 'd', 'e'])
df = pd.DataFrame(s1)3. DataFrame 的操作
访问索引和列名:
df.index df.columns选择增加修改列:
df['one'] # 选择列 df['foo'] = 'bar' # 定义固定值列 df['one_trunc'] = df['one'][:2] # 取某列的部分值 df['three'] = df['one'] * df['two'] # 新列由两列相乘 df['flag'] = df['one'] > 2 # 新列逻辑运算值 df.insert(1, 'bar', df['one']) # 插入列 del df['two'] # 删除列 three = df.pop('three') # 弹出列用方法链创建新列:
df.assign(rate=(df['one'] / df['two'])).head()选择数据:
选择列:
df[col]按索引选择行:
df.loc[label]按数字索引选择行:
df.iloc[loc]使用切片选择行:
df[5:10]用表达式筛选行:
df[bool_vec]
数据的转置:
df.T
4. DataFrame 方法
数据导入与导出
学习如何从不同数据源(如 CSV、Excel、SQL 数据库等)加载数据到 Pandas,以及如何将数据保存到这些格式中。
常用方法
读取 Excel 文件
使用 pd.read_csv('xxxx.csv') 即可读取对应文件
import pandas as pd
# 读取当前目录下 某招聘网站数据.csv
data = pd.read_csv("某招聘网站数据.csv")
# 读取前n行
data = pd.read_csv("某招聘网站数据.csv",nrows = 20)
# 跳过前n行
data = pd.read_csv("某招聘网站数据.csv",skiprows = [i for i in range(1,21)])
# 指定行读取 偶数行
data = pd.read_csv('某招聘网站数据.csv', skiprows=lambda x: (x != 0) and not x % 2)
# 指定列号读取 第 1、3、5 列
data = pd.read_csv("某招聘网站数据.csv",usecols = [0,2,4])
# 指定列名读取 positionId、positionName、salary 列
data = pd.read_csv("某招聘网站数据.csv",usecols = ['positionId','positionName','salary'])
#指定列匹配读取
'''
现在有一个 list 中包含多个字段:
usecols = ['positionId','test','positionName', 'test1','salary'
如果 usecols 中的列名存在于 某招聘网站数据.csv 中,则读取。
'''
usecols = ['positionId', 'test', 'positionName', 'test1', 'salary']
data = pd.read_csv('某招聘网站数据.csv', usecols=lambda c: c in set(usecols))
# 读取时设置索引 将 positionId 设置为索引列
data = pd.read_csv('某招聘网站数据.csv',index_col=['positionId'])
# 读取时设置标题 读取 positionId、positionName、salary 列,并将标题设置为 ID、岗位名称、薪资
data = pd.read_csv('某招聘网站数据.csv', usecols=[0,1,17],header = 0,names=['ID','岗位名称','薪资'])
读取并处理缺失值
data = pd.read_csv('某招聘网站数据.csv', keep_default_na=False) # 不将缺失值标记为 NA
data = pd.read_csv('某招聘网站数据.csv',na_values=['[]']) # 将[]标记为缺失值
data = pd.read_csv("某招聘网站数据.csv",na_filter=False) # 不处理缺失值读取时设置格式
#将 positionId,companyId 设置为字符串格式
data = pd.read_csv("某招聘网站数据.csv", dtype={'positionId': str,'companyId':str})
#将 createTime 列设置为时间
data = pd.read_csv("某招聘网站数据.csv",parse_dates=['createTime']) 分块读取
# 读取当前目录下 某招聘网站数据.csv 文件,要求返回一个可迭代对象,每次读取 10 行
data = pd.read_csv("某招聘网站数据.csv", chunksize= 10)循环读取数据
# 在 demodata 文件夹下有多个 Excel 文件,要求一次性循环读取全部文件
import os
path = 'demodata/'
filesnames = os.listdir(path)
filesnames = [f for f in filesnames if f.lower().endswith(".xlsx")]
df_list = []
for filename in filesnames:
df_list.append(pd.read_excel(path + filename))
df = pd.concat(df_list)读取 TXT 文件
import pandas as pd
data = pd.read_table("Titanic.txt")
# 含中文读取 需要读取时设置编码
data = pd.read_table("TOP250.txt",encoding='gb18030')
# data = pd.read_csv("TOP250.txt",encoding='gb18030',sep = '\t') # 使用 read_csv 也可读取 JSON 文件
import pandas as pd
data = pd.read_json("某基金数据.json")读取 SQL
# 为了方便统一操作,我们先执行下面的代码创建数据
from sqlite3 import connect
import pandas as pd
conn = connect(':memory:')
df = pd.DataFrame(data=[[0, '10/11/12'], [1, '12/11/10']],
columns=['int_column', 'date_column'])
df.to_sql('test_data', conn)
# 在 pandas 中直接使用 SQL 语句操作数据库,并将结果返回为 dataframe
pd.read_sql('SELECT int_column, date_column FROM test_data', conn)读取 HDF5 文件
读取网页
import pandas as pd
pd.read_html("https://baike.baidu.com/item/2020%E5%B9%B4%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A/10188878?fromtitle=%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A&fromid=3250130&fr=aladdin")[6].head(5)读取剪贴板
import pandas as pd
# data = pd.read_clipboard()数据存储
# 保存为 CSV
data.to_csv("out.csv",encoding = 'utf_8_sig')
# 指定列保存
## 将读取 Excel 文件中读取到的数据保存为 csv 格式至当前目录下(文件名任意),且只保留positionName、salary两列
data.to_csv("out.csv",encoding = 'utf_8_sig',columns=['positionName','salary'])
# 取消索引
## 将读取 Excel 文件中读取到的数据保存为 csv 格式至当前目录下(文件名任意),且取消每一行的索引
data.to_csv("out.csv",encoding = 'utf_8_sig',index = False)
# 标记缺失值
## 在上面的基础上,在保存的同时,将缺失值标记为'数据缺失'
data.to_csv("out.csv",encoding = 'utf_8_sig',index = False,na_rep = '数据缺失')
# 保存为 ZIP
compression_opts = dict(method='zip',
archive_name='out.csv')
data.to_csv('out.zip', index=False,
compression=compression_opts)
# 保存为 Excel
data.to_excel("test.xlsx")
# 保存为 JSON
data.to_json("out.json")
# 保存为 Markdown
data.head().to_markdown(index = None)
# 保存为 Html 取消行索引 标题居中对齐 列宽100
data.to_html("out.html", col_space=100,index = None,justify = 'center',border = 1)数据评估与清洗
整洁数据的结构三要点:
每列是一个变量
每行是一个观察值
每个单元格是一个值

脏数据(需要清理的数据)
丢失数据
重复数据
不一致数据
无效或错误数据
数据评估
查看数据(head(), tail(), info())和选择数据(基于标签的索引 loc[] 和基于位置的索引 iloc[])。
数据预览
# 数据维度 先看看数据多少行,多少列,对接下来的处理量心里有个数
df.shape # (262, 11)
# 查看数据量
## 数据框的 行 * 列,总共单元格的数量
df.size
# 数据抽样 随机查看一个样本,大致了解下数据
df.sample()
# df.sample(n) #抽n个样本
# 检查头尾数据
df.head(3)
df.tail() # 查看后5行
# 查看数据基本信息
df.info()
# 查看数值数据统计信息
df.describe().round(2) # 小数点后保留2位
# 查看离散数据统计信息
df.describe(include=['O'])缺失值检查
# 检查全部缺失值
df.isna().sum().sum()
# 检查每列缺失值
df.isnull().sum()
# 定位缺失值
df[df.isnull().T.any() == True]
# 高亮缺失值
(df[df.isnull().T.any() == True]
.style
.highlight_null(null_color='skyblue')
.set_table_attributes('style="font-size: 10px"')
)重复值检查
# 查找全部重复值
df[df.duplicated()]
# 查找指定列重复值
df[df.duplicated(['片名'])]数据统计
# 统计信息|频率
df.省市.value_counts()
# 统计信息|均值
df.总分.mean()
# 统计信息|中位数
df.总分.median()
# 统计信息|众数
df.总分.mode()
# 统计信息|部分
#计算 总分、高端人才得分、办学层次得分的最大最小值、中位数、均值
df.agg({
"总分": ["min", "max", "median", "mean"],
"高端人才得分": ["min", "max", "median", "mean"],
"办学层次得分":["min", "max", "median", "mean"]})
# 统计信息|完整
#查看数值型数据的统计信息(均值、分位数等),并保留两位小数
df.describe().round(2)
# 统计信息|分组
#计算各省市总分均值
df.groupby("省市")['总分'].mean()
# 统计信息|相关系数
#也就是相关系数矩阵,也就是每两列之间的相关性系数
df.corr() 数据排序
# 升序
df.sort_values(by='总分', ascending=True).head(20) #将数据按照总分升序排列,并展示前20个学校
# 指定列排序
df.nlargest(10, '高端人才得分') # 将数据按照 高端人才得分 降序排序,展示前 10 位
# 分列排名
df.iloc[:,3:].idxmax() # 查看各项得分最高的学校名称数据清洗
数据结构清洗
修改列名/索引
# 修改列名 rename()默认不改变原数据,参数inplace=True时原地修改原数据
## 将原 df 列名 Unnamed: 2、Unnamed: 3、Unnamed: 4 修改为 金牌数、银牌数、铜牌数
df.rename(columns={'Unnamed: 2':'金牌数',
'Unnamed: 3':'银牌数',
'Unnamed: 4':'铜牌数'},inplace=True)
# df.rename(index={……}) # 修改索引
# 不仅可以传入字典,还可以传入函数或方法
# 修改行索引
## 将第一列(排名)设置为索引
df.set_index("排名",inplace=True)
## 把索引重设为初始默认的位置索引,并且把原本作为index的值变成单独一列
df.reset_index()
## 索引排序
df.sort_index()
# 修改索引名
## 修改索引名为 金牌排名
df.rename_axis("金牌排名",inplace=True)转置
每列是一个变量,每行是一个观察值。相反时进行转置处理df.T。
拆分
# 拆分列 str.split(" ",expand=True),expand=True表示拆分到不同列
## 将 人口密度 拆分为 人口 和 面积
df[["人口","面积"]]=df["人口密度"].str.split("/",expand=True)
# 删除拆分前的列 df2=df2.drop("人口密度",axis=1)
# 合并列 str.cat(),参数sep指定拼接时的分隔符
df["姓"].str.cat(df["名"],sep="-")
# 将一部分 列名 转换为 变量的值,pd.melt()
pd.melt(df4,id_vars=["国家代码","年份"],var_name="年龄组",value_name="肺结核病例数")
# id_var:保存原样的列,其余都被视为需要转换的列
# var_name:转换后包含原本列名值的新列列名
# value_name:转换后包含原本变量值的新列列名
# 拆分行
df.explode("课程列表")数据内容清洗
处理缺失值(dropna(), fillna())、删除重复值(drop_duplicates())和数据类型转换(astype())。
丢失数据:人工填入 不处理缺失值 删除缺失值行 填充值填入
重复数据:删除重复值
不一致数据:统一不一致数据
无效或错误数据:删除或替换
转换数据类型
数据修改
# 修改值
## 将 ROC(第一列第五行)修改为 俄奥委会
df.iloc[4,0] = '俄奥委会'
# 替换值(单值)
## 将金牌数列的数字 0 替换为 无
df['金牌数'].replace(0,'无',inplace=True)
# 替换值(多值)
## 同时替换,将 无 替换为 缺失值,将 0 替换为 None
## 注意:缺失值的 Nan 该怎么生成?
import numpy as np
df.replace(['无',0],[np.nan,'None'],inplace = True)
# 修改类型
## 将 金牌数 列类型修改为 int
df['金牌数'] = df['金牌数'].fillna('0').astype(int)数据增加
# 新增列(固定值)
## 新增一列 比赛地点,值为 东京
df['比赛地点'] = '东京'
# 新增列(计算值)
## 新增一列 金银牌总数列,值为该国家金银牌总数
df = df.replace('None',0)
df['金银牌总数'] = df['金牌数'] + df['银牌数']
# 新增列(比较值)
## 新增一列 最多奖牌数量 列,值为该国金银牌数量种最多的一个奖牌数量,例如美国银牌最多,则为41,中国为38
df['最多奖牌数量'] = df.bfill(1)[["金牌数", "银牌数",'铜牌数']].max(1)
# 新增列(判断值)
## 新增一列 金牌大于30,如果一个国家的金牌数大于 30 则值为 是,反之为 否
df['金牌大于30'] = np.where(df['金牌数'] > 30, '是', '否')
# 增加多列
# #新增两列,分别是,金铜牌总数(金牌数+铜牌数),银铜牌总数(银牌数+铜牌数)
df = df.assign(金铜牌总数=df.金牌数 + df.铜牌数,
银铜牌总数=df.银牌数+df.铜牌数)
# 新增列(引用变量)
## 新增一列金牌占比,为各国金牌数除以总金牌数(gold_sum)
gold_sum = df['金牌数'].sum()
df.eval(f'金牌占比 = 金牌数 / {gold_sum}',inplace=True)
# 新增行(末尾追加)
## 在 df 末尾追加一行,内容为 0,1,2,3… 一直到 df 的列长度
df1 = pd.DataFrame([[i for i in range(len(df.columns))]], columns=df.columns)
df_new = df.append(df1)
# 新增行(指定位置)
## 在第 2 行新增一行数据,即美国和中国之间。
df1 = df.iloc[:1, :]
df2 = df.iloc[1:, :]
df3 = pd.DataFrame([[i for i in range(len(df.columns))]], columns=df.columns)
df_new = pd.concat([df1, df3, df2], ignore_index=True)数据删除
# 删除指定行
## 删除 df 第一行
df.drop(1)
# 删除条件行
df.drop(df[df.金牌数<20].index)
# 删除列
## 删除刚刚新增的 比赛地点 列
df.drop(columns=['比赛地点'],inplace=True)
# 删除列(按列号)
## 删除 df 的 7、8、9、10 列
df.drop(df.columns[[7,8,9,10]], axis=1,inplace=True)缺失值处理
# 缺失值处理
# 删除缺失值 参数 subset 指定列检查缺失值
df = df.dropna()
# 整体填充补全 将全部缺失值替换为 *
df = df.fillna('*')
# 向上填充补全
##将评分列的缺失值,替换为上一个电影的评分
df['评分'] = df['评分'].fillna(axis=0,method='ffill')
# 整体均值填充补全
##将评价人数列的缺失值,用整列的均值进行填充
df['评价人数'] = df['评价人数'].fillna(df['评价人数'].mean())
# 上下均值填充补全
##将评价人数列的缺失值,用上下数字的均值进行填充
df['评价人数'] = df['评价人数'].fillna(df['评价人数'].interpolate())
# 匹配填充补全
##填充 “语言” 列的缺失值,要求根据 “国家/地区” 列的值进行填充
df['语言']=df.groupby('国家/地区').语言.bfill()重复值处理
# 删除全部重复值 参数 subset 指定列检查
df = df.drop_duplicates()
# 保留重复值 保留最后一次出现的值 参数keep默认保留第一次出现的
df = df.drop_duplicates(keep = 'last')值替换
# df.replace()
df["学校"].replace("清华","清华大学")
df.replace(["清华","五道口职业技术学院","Tsinghua University"],"清华大学")
df.replace({"华南理工":"华南理工大学",
"清华:"清华大学",
"北大:"北京大学",
"中大":"中山大学"})数据类型转换
# s.astype()
s1.astype(int) # 转换成 整数
s1.astype(str) # 转换成 字符串
s1.astype(float) # 转换成 浮点数
s1.astype(bool) # 转换成 布尔值
……
# python中字符串显示为object,category为分类数据数据筛选
筛选列
# 通过列号
## 提取第 1、2、3、4 列
df.iloc[:,[0,1,2,3]]
# 通过列名
## 提取 金牌数、银牌数、铜牌数 三列
df[['金牌数','银牌数','铜牌数']]
# 条件(列号)
## 筛选全部 奇数列
df.iloc[:,[i%2==1 for i in range(len(df.columns))]]
# 条件(列名)
## 提取全部列名中包含 数 的列
df.loc[:, df.columns.str.endswith('数')]
# 组合(行号+列名)
## 提取倒数后三列的10-20行
df.loc[10:20, '总分':] 筛选行
# 通过行号
## 提取第 10 行
df.loc[9:9]
# 通过行号(多行)
## 提取第 10 行之后的全部行
df.loc[9:]
# 固定间隔
## 提取 0-50 行,间隔为 3
df[:50:3]
# 判断(大于)
## 提取 金牌数 大于 30 的行
df[df['金牌数'] > 30]
# 判断(等于)
## 提取 金牌数 等于 10 的行
df.loc[df['金牌数'] == 10]
# 判断(不等于)
## 提取 金牌数 不等于 10 的行
df.loc[~(df['金牌数'] == 10)]
# 条件(指定行号)
## 提取全部 奇数行
df[[i%2==1 for i in range(len(df.index))]]
# 条件(指定值)
## 提取 中国、美国、英国、日本、巴西五行数据
df.loc[df['国家奥委会'].isin(['中国','美国','英国','日本','巴西'])]
# 多条件
## 在上一题的条件下,新增一个条件:金牌数小于30
df.loc[(df['金牌数'] < 30) & (df['国家奥委会'].isin(['中国','美国','英国','日本','巴西']))]
# 条件(包含指定值)
## 提取 国家奥委会 列中,所有包含 国的行
df[df.国家奥委会.str.contains('国')]组合筛选
# 筛选某行某列
## 提取 第 0 行第 2 列
df.iloc[0:1,[1]]
# 筛选多行多列
## 提取 第 0-2 行第 0-2 列
df.iloc[0:2,[0,1]]
# 组合(行号+列号)
## 提取第 4 行,第 4 列的值
df.iloc[3,3]
# 组合(行号+列名)
## 提取行索引为 4 ,列名为 金牌数 的值
df.at[4,'金牌数']
# 条件
## 提取 国家奥委会 为 中国 的金牌数
df.loc[df['国家奥委会'] == '中国'].loc[1].at['金牌数']
# query
## 使用 query 提取 金牌数 + 银牌数 大于 15 的国家
df.query('金牌数+银牌数 > 15')
# query(引用变量)
## 使用 query 提取 金牌数 大于 金牌均值的国家
gold_mean = df['金牌数'].mean()
df.query(f'金牌数 > {gold_mean}')数据整理
对数据进行转换,包括重塑(
pivot_table(),melt())、合并(merge(),concat())和分组(groupby())。描述性统计(
describe())、相关性分析(corr())和数据聚合(agg())。
数据拼接与合并
从多个数据源获取相关数据,或者是数据集本身包括了多个表,就可能涉及一些数据连接或合并等操作。concat()、merge()、join()
拼接数据
"concat"用于简单拼接
# 拼接
pd.concat([df1,df2])
# 忽略索引:"ignore_index=True",重置索引从0开始
pd.concat([df1,df2],ignore_index=True)
# 横向拼接,"axis=1"
pd.concat([df1,df2],axis=1)合并数据
"merge"用于基于列值的高级合并
"join"用于基于索引的合并
# 使用"merge"方法,基于某列的匹配进行连接,通过"on"参数指定合并列
pd.merge(df1,df2,on="某列名")
# 根据多列的值同时匹配
pd.merge(df1,df2,on=["列名1","列名2"])
# 处理列名不一致:使用"left_on"和"right_on"
pd.merge(df1,df2,left_on=["列名1","列名2"],right_on=["列名11","列名22"])
# 多列合并重名列默认自动加_x,_y为后缀,也可以使用"suffixes"参数指定后缀
pd.merge(df1,df2,on=["列名1","列名2"],suffixes=["_df1","_df2"])
# 合并类型:"inner", "outer", "left", "right"
#"inner"保留两表中匹配的行,
# "outer"保留两表中所有行,不匹配的使用NaN填充,
#"left"保留左表所有行,右表根据左表匹配,不匹配的使用NaN填充,
#"right"保留右表所有行,左表根据右表匹配,不匹配的使用NaN填充。
pd.merge(df1,df2,on="某列名",how="inner")
# join是根据索引去进行合并,重名列必须指定后缀,否则报错
df1.join(df2,how='inner',lsuffix='_df1',rsuffix='_df2')数据分组与聚合
分组:根据特定变量将数据划分为不同的组。
聚合:对分组后的数据执行汇总操作,如求和、求平均等。
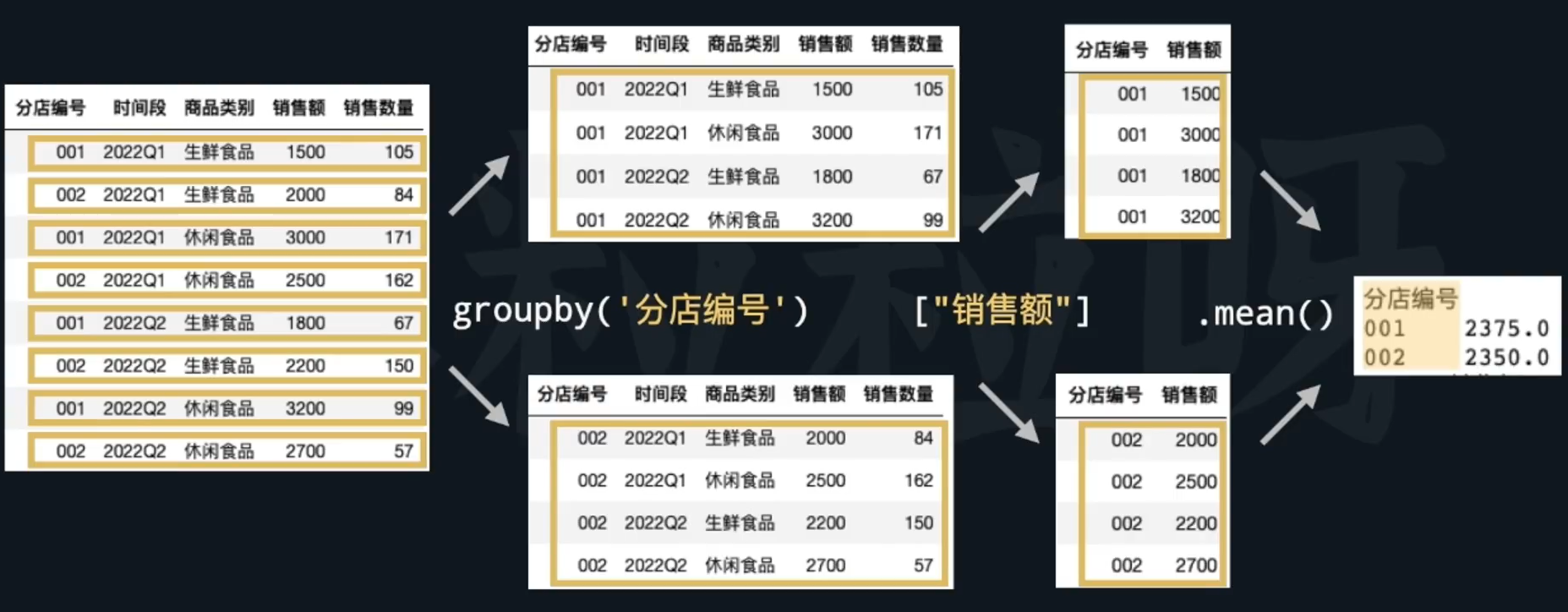
使用
groupby()方法根据特定变量分组。数据透视表(Pivot Table),基于原始数据进行表格结构重塑,方便数据分析和展示。使用
pivot_table()函数,指定"index", "columns", "values", "aggfunc"参数进行数据透视。pivot_table()与groupby()的区别:pivot_table()可以同时指定索引和列进行分组聚合,提供更灵活的数据展示方式。groupby()更适合直接的分组聚合运算,逻辑直接。
# 把df针对分店编号和时间段记进行分组,计算销售额和销售数量的平均值
df.groupby(["分店编号","时间段"])[["销售额","销售数量"]].mean()
# 把df的分店编号和时间段作为索引,商品类别作为列,计算销售额的总和
pd.pivot_tabte(df,index=["分店编号","时间段"],columns="商品类别",values="销售额",aggfunc=np.sum)
pd.cut()函数:根据数字范围划分series,并返回带有标签的分类数据
# 1、定义年龄分组列表:[0,10,20,30,40,50,60,120]
# 2、并根据以上分组对df1的年龄列进行分箱
age_bins=[0,10,20,30,40,50,60,120]
pd.cut(df1["年龄"],age_bins)
# 1、定义分组标签列表:["儿童","青少年","青年","壮年","中年","中老年","老年"]
# 2、根据上面定义的分组对df1的年龄列进行分箱,并使用以上分组标签
# 3、最后为df1新建"年龄组"列,值为以上分组标签
age_labets=["儿童","青少年","青年","壮年","中年","中老年","老年"]
df1["年龄组"] = pd.cut(df1["年龄"],age_bins,labels=age_labels)数据筛选:使用query()方法根据条件筛选DataFrame
# 用query方法筛选出性别为男且年龄小于或等于28岁的观察值
df1.query('(性别 == "男") & (年龄 <= 28)')数据分组
将一个 DataFrame 根据一定的规则拆分为多个组合,并应用不同的函数进行计算,pd.groupby接收多个参数(DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)),但整体思想如下图简单的过程所示,即分组 + 计算 输出不同地区员工的平均薪资
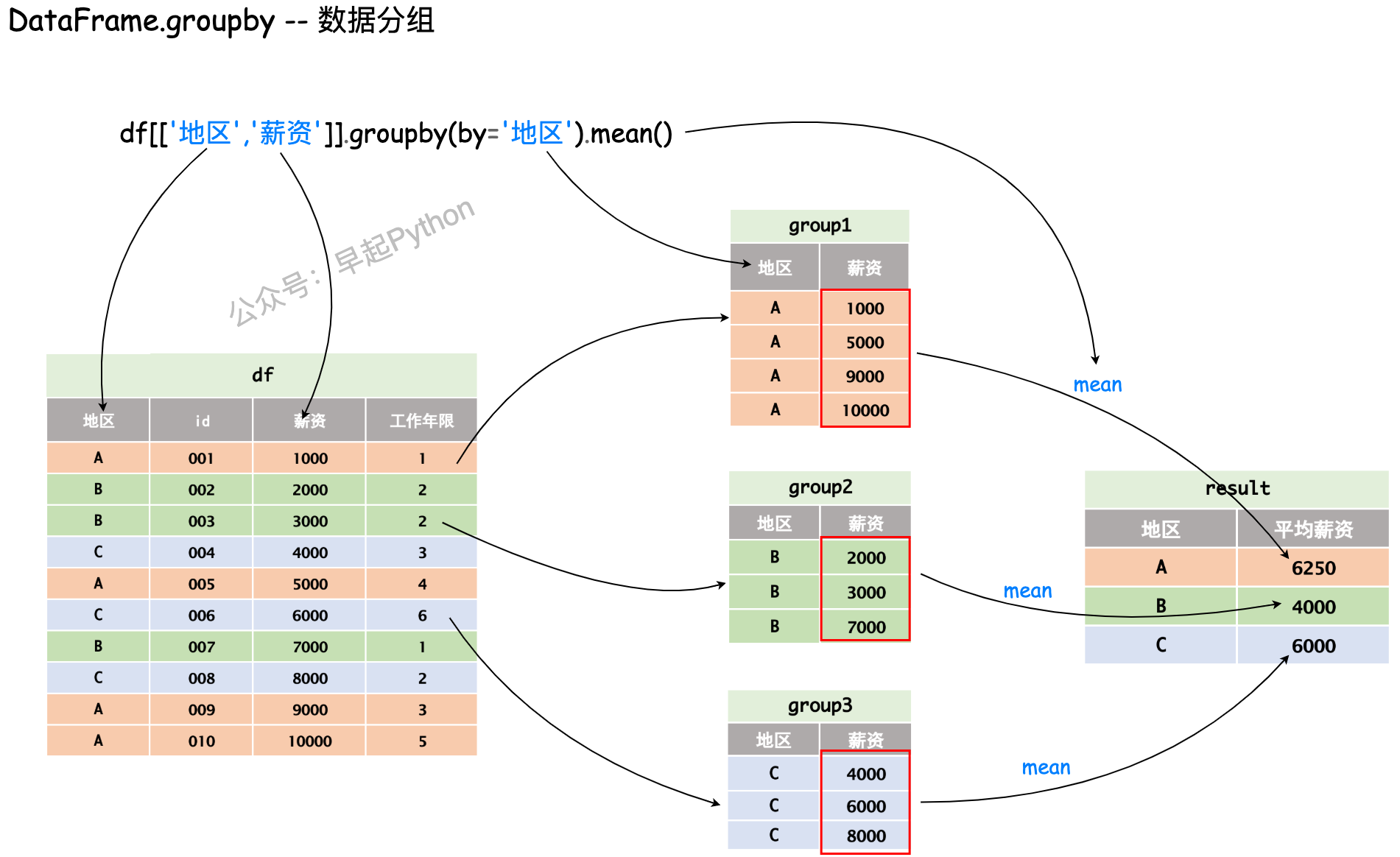
分组统计
# 均值
## 计算各区(district)的薪资(salary)均值
df[['district','salary']].groupby(by='district').mean()
# df.groupby("district")['salary'].mean()
取消索引
重新按照上一题要求进行分组,但不使用 district 做为索引
df.groupby("district", as_index=False)['salary'].mean()
排序
计算并提取平均薪资最高的区
df[['district','salary']].groupby(by='district').mean().sort_values('salary',ascending=False).head(1)
频率
计算不同行政区(district),不同规模公司(companySize)出现的次数
pd.DataFrame(df.groupby("district")['companySize'].value_counts())
# df.groupby(['district','companySize']).size()
修改索引名
将上一题的索引名修改为 district -> 行政区 companySize -> 公司规模
pd.DataFrame(df.groupby("district")['companySize'].value_counts()).rename_axis(["行政区", "公司规模"])
计数
在上一个操作的基础上,统计每个区出现的公司数量
df.groupby("district")['companySize'].count()分组查看
查看各组信息
将数据按照 district、salary 进行分组,并查看各分组内容
df.groupby(["district",'salary']).groups
查看指定条件信息
将数据按照 district、salary 进行分组,并查看西湖区薪资为 30000 的工作
df.groupby(["district",'salary']).get_group(("西湖区",30000))分组规则
过匿名函数1
根据 createTime 列,计算每天不同 行政区 新增的岗位数量
pd.DataFrame(df.groupby([df.createTime.apply(lambda x:x.day)])[
'district'].value_counts()).rename_axis(["发布日", "行政区"])
通过匿名函数2
计算各行政区的企业领域(industryField)包含电商的总数
df.groupby("district", sort=False)["industryField"].apply(
lambda x: x.str.contains("电商").sum())
通过内置函数
通过 positionName 的长度进行分组,并计算不同长度岗位名称的薪资均值
df.set_index("positionName").groupby(len)['salary'].mean()
通过字典
将 score 和 matchScore 的和记为总分,与 salary 列同时进行分组,并查看结果
df.groupby({'salary':'薪资','score':'总分','matchScore':'总分'}, axis=1).sum()
通过多列
计算不同 工作年限(workYear)和 学历(education)之间的薪资均值
pd.DataFrame(df['salary'].groupby([df['workYear'], df['education']]).mean())数据聚合
数据聚合可以在数据分组的基础上,进一步对不同列采取不同的计算规则,例如查看不同地区的员工薪资最大、最小、均值以及工作年限的均值。
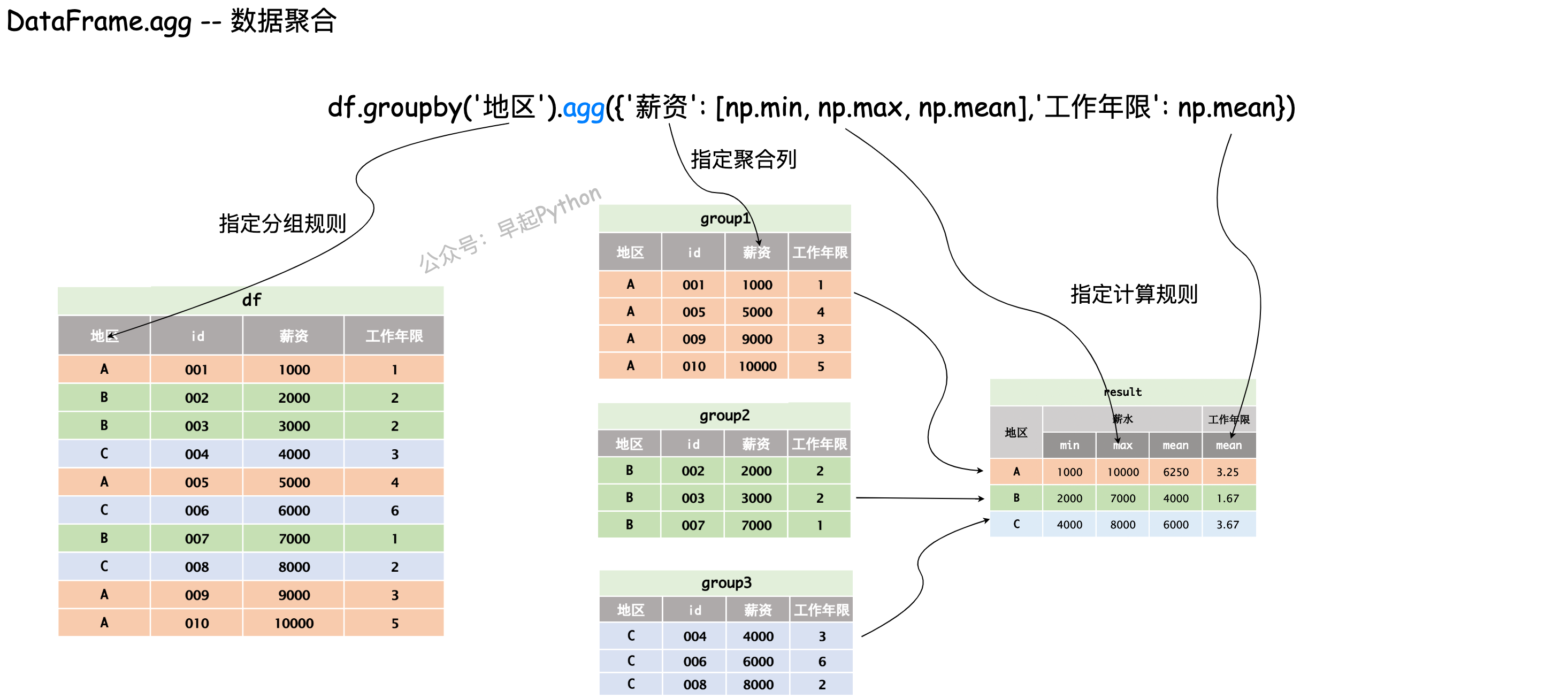
计算指标
分组计算不同行政区,薪水的最小值、最大值和平均值
import numpy as np
df.groupby('district')['salary'].agg([min, max, np.mean])修改列名
将上一题的列名(包括索引名)修改为中文
df.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=(
'salary', 'max'), 平均工资=('salary', 'mean')).rename_axis(["行政区"])组合计算
对不同岗位(positionName)进行分组,并统计其薪水(salary)中位数和得分(score)均值
df.groupby('positionName').agg({'salary': np.median, 'score': np.mean})多层统计
对不同行政区进行分组,并统计薪水的均值、中位数、方差,以及得分的均值
df.groupby('district').agg(
{'salary': [np.mean, np.median, np.std], 'score': np.mean})自定义函数
在 18 题基础上,在聚合计算时新增一列计算最大值与平均值的差值
def myfunc(x):
return x.max()-x.mean()
df.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=(
'salary', 'max'), 平均工资=('salary', 'mean'), 最大值与均值差值=('salary', myfunc)).rename_axis(["行政区"])